How to provide network connectivity at your hacker con
[Disclaimer: IANANetwork Engineer. This post is specifically about the end-user experience, or even more specifically about my end-user experience.]
So I recently attended both BSides Leeds and Steelcon. Let's start with BSides Leeds. This was located in Cloth Hall Court, which seems to have some academic affiliation such that wireless internet was provided by eduroam.
I am not an academic and so do not have eduroam credentials. Luckily there were sheets of paper everywhere detailing how to acquire some for the duration. These involved some kind of dance involving sending an SMS. I didn't even attempt this (my phone had no credit for sending SMSes) but I was able to persuade someone who had been through the dance to share with me the creds they had apparently acquired. I promptly wrote these down on the sheet of paper to hopefully save the next person to come along some annoyance. (Is this kind of credential-sharing frowned upon? I don't even know but I had a vague sense of unease the whole time, as though I was somehow doing something wrong even though I was just trying to gain connectivity for myself and help others who came after me do the same.)
Ultimately it was moot though, as my laptop simply hung when connecting to eduroam without asking for wifi creds at all. No of course there were no diagnostics why would there be?
There were also ethernet jacks in the wall. These gave me an IPv6 address that didn't route anywhere and then went down after thirty seconds. Apparently they also required some kind of dance that my laptop was not performing. No sheets of paper this time. I had no network connectivity the entire conference.
Two weeks later I went to Steelcon. This was hosted at an actual academic institution (Sheffield Hallam University) and so eduroam again.
This time the sheets of paper dotted around picked a different approach. If you weren't using eduroam you could connect to the Sky wifi network where there was a URL you could visit to register for a free guest wifi account. The thought of having to wade through corporate bullshit to get on the network immediately made my heart sink. Ultimately I failed at the first hurdle, reaching their marketing-heavy landing page but not seeing how to progress further. Pretty soon I gave up on Sky wifi.
But, a miracle! My friend Bonzi was able to hook me up with some eduroam creds. It was at this point that I discovered the reason for my recent BSides eduroam failure, namely that I already had some stale eduroam creds that I'd apparently needed for the previous BSides Leeds in 2020. (Why this authentication failure was not communicated up the stack is a mystery to me, but I was running an absolutely vanilla Xubuntu installation.)
And slowly, as I dusted off old neurons, a memory of the network connectivity at that event surfaced: having to use 3G to get my home ssh server to listen on a different port because port 22 was blocked. (I seem to recall I picked 465, which IANA allocated to SMTP-over-TLS.)
Happily port 22 was not blocked this time, but ICMP was, which threw me briefly because who doesn't check their internet is working by pinging google?
And, finally, life was good. But, man...
Internet connectivity should be a given. It should not require a separate already-connected device to set up. It should not be an excuse for marketing. It should not rely on you being affiliated with any particular organization to make it easy, or to make it work at all. In particular it should not depend on who you know who can help you out. Blocking arbitrary ports and protocols just causes people headaches: in particular port 22 not working at a hacker con is ridiculous.
By contrast, here's how to do it right. Here's the Network page on the EMFcamp 2022 wiki (mirror, because it'll undoubtedly change by the time the next EMF comes along in 2024).
And here's what I like about that page:
- There's a wiki page! Tells you everything you need to know, before the event.
- Creds are simple, memorable and easy to type. (Bonzi's eduroam creds were around two dozen characters, including fun ones such as @. Happily I had an actual laptop with keyboard, but I still managed to make a typo.)
- You can set up your headless Pi or internet-connected paperweight or other random IoT widget in advance. You don't need a web browser on the device. No captive portals. No "be sure to agree to the terms and conditions". No "we'll need your email address". No "you like cookies, right?". No hoops of any kind. Ten seconds, done.
- The following text: "We operate an unfiltered network that is wide open to the Internet. There is no NAT, and everybody has a public IP address. This is our definition of "network neutrality" - a network that doesn't do anything whatsoever to your IP connection." This is so freaking rare these days. I didn't take advantage of this personally but simply reading that text instantly communicated to me that this network is run by passionate people who believe in the principle of end-to-end transparency that the internet was built around and that made it the world-changer it is today: in the event of a problem I would have full confidence the organizers had my back. I encountered no problems whatsoever. Let's not forget this was in a field in the middle of nowhere. Mad, mad respect, guys.
I had a similarly stellar experience with the network at CCC the twice I've been.
Three nuclear power plant simulators
With the world in the grip of Chernobyl fever I figured I'd go see what was out there by way of nuclear power plant simulators. I've not seen the TV series, but as someone who's long been fascinated by this kind of intricate disaster, causing a meltdown in the safety of your own home sounds like a no-brainer in terms of fun. So with high hopes I googled "nuclear reactor simulator".
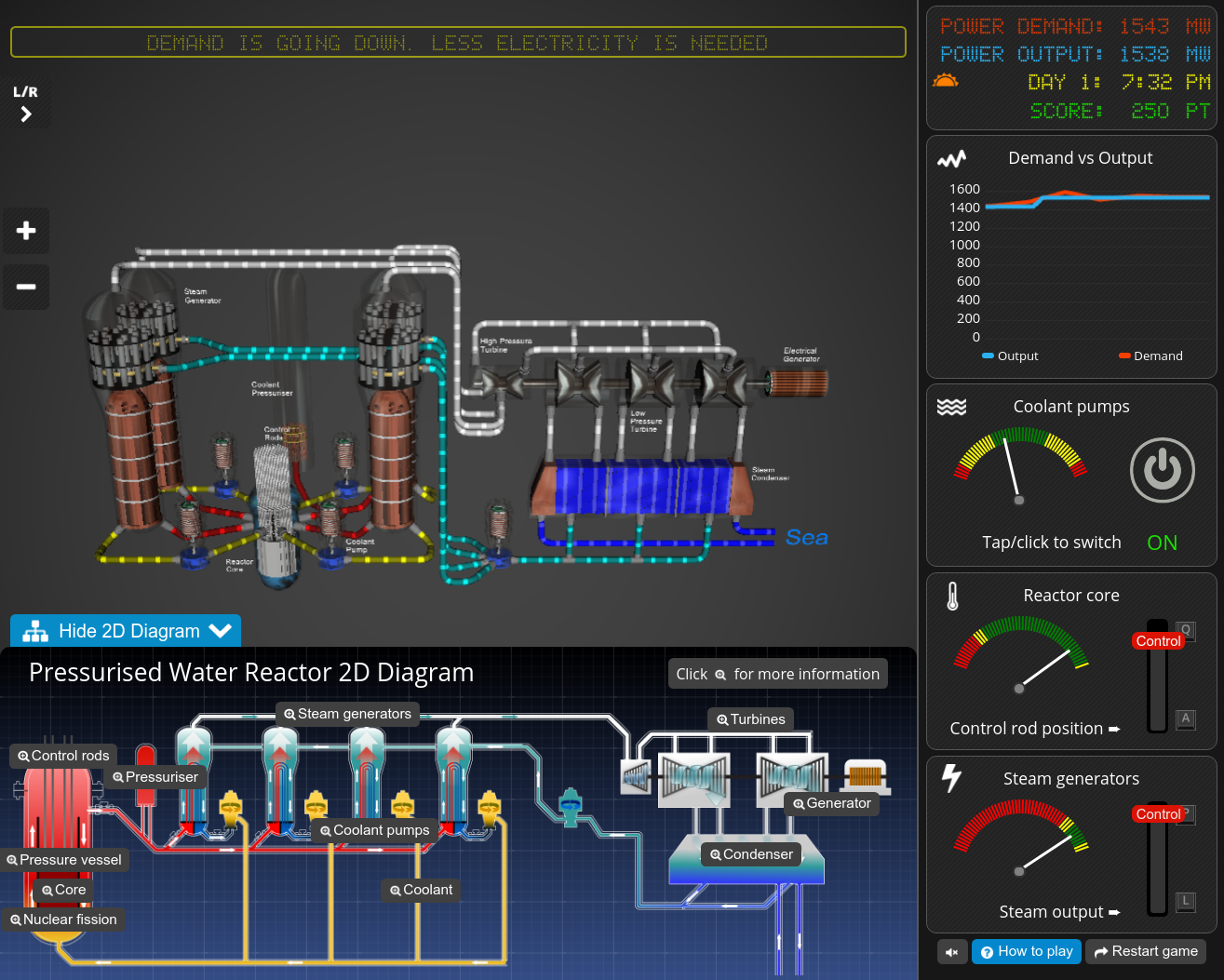
First up is the University of Manchester's Nuclear Reactor Simulator.
It's of the "modern" school of casual gaming, where everything is better with narration and tutorials and fancy animations on the assumption that players have the attention span of a goldfish. Seriously, it's a nuclear reactor simulator. Why would you be interested in such a thing if you weren't at least slightly detail-oriented?
But looking past that, you have a total of two controls (not counting the coolant pump switch which you should never touch except to switch it on and leave it there). They control two dials that you have to keep in the green and out of the red. What do green and red represent? Who the hell knows? There's no numbers of any kind.
Actually I lie. It does come with fun factoids about how much fuel a nuclear plant might use in a year compared to a fossil fuel plant. Yes, actual numbers, but included for no other reason than to dazzle.
Verdict: complete waste of time.
Next is nuclearpowersimulator.com.
This is straight out of the late nineties despite being made in 2012, replete with gratuitous animated GIFs, textured backgrounds and and sliders you can't drag. (Also an inexplicable fondness for BiCapitalization.)
But you do have *three* controls this time, and eight parameters you have to keep within bounds. They actually have numbers, although figuring out what units they're in is a puzzle unto itself.
There's also some token attempt at making it a kind of management sim where you have to turn a profit, but it's terribly balanced.
The idea is that you get paid per watt you put on the grid, and you have fixed expenses plus the cost of repairing any bits you inadvertently redline. This is all well and good except that going over the arbitrary thresholds by 1% causes precisely the same damage as going over by 50%, which makes no sense whatsoever.

You'd think that damaging hardware would be orders of magnitude more expensive than whatever profit you might make at the wheel, but it turns out that repairs and even fines for being forced to vent radioactive steam into the atmosphere make basically no impact on your bottom line (which, incidentally, is typically in the tens of millions, and shown as an integer--yes! of course having to parse 8-digit numbers at a glance is a good idea).
It has a saving grace, namely that your fuel burns up as you go. So not only do you need to spend money on refuelling, but you have to balance at what point you want to refuel. Too early and you waste money replacing still-viable fuel, too late and you're struggling to maintain the power output of your reactor as it gets increasingly unstable.
This has the potential to be awesome, but instead the game imposes an arbitrary cutoff of "20%" at which you must replace your fuel. And refuelling, like other repairs, is instantaneous and does not require that you shut down the reactor first. Which is a complete shame, because one of the other potentially fun balancing acts you have to perform is how fast you get your reactor up to its rated power output. Too slow and you're losing potential income as you ramp up bit by bit, too fast and you're paying through the nose for running the power-hungry coolant pumps full blast on external grid power while your core gets up to temperature, all the while being careful not to overshoot and cause a meltdown.
Sadly the amount of actual simulation it does is extremely minimal. The game mechanics occupy about a page of unminified javascript. I trust its physics not at all.
And then there's the bizarre "Secondary flow cannot exceed 65% of Heat Exchanger temperature. Increase Heat Exchanger temperature or reduce Secondary Coolant flow.".
What is "secondary flow"? It has a maximum of 250 whatevers. Is that degrees Celsius like the heat exchanger temperature is? What basis in reality does such a constraint have? Is it a safety feature? How is multiplying (non-absolute) temperatures ever a good idea?
To be clear, "cannot exceed" means the game automatically turns it down for you. But surely the point of such a simulation is to let you find out the consequences firsthand rather than prohibiting you from doing bad things. As it is, I suspect it's there solely to make the game less trivial.
Verdict: mildly compelling, very little basis in reality, so much low-hanging fruit.
And finally we come to the turd that is Power Plant Simulator.

This is like Tabletop Simulator in that controls that would be straightforward in 2D are instead rendered in a virtual environment you can move around. Also like TTS it is payware and runs under Windows.
But that is not what makes it a turd. It is a turd because it periodically lights up a display that you have to copy onto adjacent controls within a time limit otherwise it catches fire.
What does this have to do with a nuclear power plant? Nothing.
I have no idea why anyone would pay $3.99 for such a thing. Judging by the youtube comments, maybe the Simpsons is responsible for most of its sales. Certainly the realism is Simpsons-level.
Verdict: nggggghhhh.
And that's my patience for today. If anyone knows of any actual simulators that understand, say, xenon poisoning and cavitation (to name just two of the things that make the Chernobyl disaster interesting) but that are nonetheless intelligible to someone whose knowledge of nuclear physics is due entirely to late-night wikipedia sessions, by all means let me know.
BeebSides
So I wrote a flag[0] for BSides Leeds 2019.
The aim was simple: load and display an image from an audio source on a BBC micro, as inspired by an Easter egg in the recent Black Mirror episode Bandersnatch which did the same on the Spectrum. But I'm nothing if not a perfectionist so I went kind of nuts on the size optimization, turning what should have taken an hour or two into a week-long odyssey.
There's also a tune. More on that later.
An aside: assembly fragments in this article are mostly generated by beebasm, which has all-caps mnemonics and hex digits, uses Beeb-style & to mean hexadecimal, and marks labels with a preceding dot. OS disassemblies are by dxa, which has lower-case mnemonics and hex digits, uses $ to mean hexadecimal, and suffixes labels with a colon. Code is on github for those following along at home.
Stage 0: the header
Acorn's OS stores files on tape in blocks of up to 256 bytes.[1] Each block has a header, containing the filename, block number, the load and execution address (in every block, although only meaningful for the first), and a CRC.[2]
Since we'd like to minimize loading time this is overhead we'd really like to dispense with, so our first order of business will be to replace the OS's tape loading routines with our own that have none of this guff. Happily, now that all the mundane annoyances of using cassette tapes as a reliable data storage medium (wobble, hiss, dropouts, &c.) have vanished into history this works just fine.
Milestones achieved: prints our filename, and its length in (hex) bytes.
2a synchronisation byte, indicates start of header
42 65 65 62 53 69 64 65 73 00 filename "BeebSides", zero-terminated
00 05 ff ff load address: &FFFF0500 (FFs mean "load in I/O space if on a second processor")
09 05 ff ff exec address: &FFFF0509
00 00 block number: 0
75 00 block length: &75
80 flags: &80 for "last block of the file"
e1 8c e2 00 reserved bytes, see later
96 cc CRC16: &CC96
Stage 1: data block
The actual block of data we promised would follow the header. Ideally we'd like only one block, which restricts us to 256 bytes of code. But this is doable.
Milestones achieved: OS beeps to indicate loading has finished, turns the tape off, and starts running our code!
Maybe. See, there's a kind of hitch. We don't actually know what the OS is gonna do. It depends upon what the user asked for. Now ideally we'd like it to have just loaded our code at the address we specified, and now go and execute it (again at the address we specified). Indeed it's possible to enforce that this is the only thing the OS will do with our code, by setting a "protection" bit in the header. This ensures that loading-but-not-executing it, loading it somewhere else, loading only part of it &c. are all verboten, and also does some convenient other things to ensure you can't easily read what was just loaded, such as disabling aborting loading with the Escape key, and ensuring that all memory gets zeroed out if you reset the machine by pressing Break.[3]
Sadly, we're not gonna do that. It's unlikely that the command for run-this-machine-code-program would be the first thing someone would try. Instead, approximately 99% of software on tape had a BASIC program at the beginning, and was run by asking BASIC, not the OS. BASIC would load the file into the BASIC program storage area starting at PAGE, ignoring the load address, and proceed to look for BASIC instructions to interpret. Almost everyone who ever used tapes on a Beeb will have used the command to do this, whereas it was entirely possible to get by without knowing that there even existed other ways of running a program.
So with a protected file, people would likely try load-as-BASIC first and get the I'm-afraid-I-can't-do-that-Dave error Locked. And as a CTF at a security conference such an error is less likely to elicit a reaction of "guess I shouldn't do that then" and more "so how do I unlock it?", the answer to which Google is perfectly happy to provide[4]. And thus would people be led astray.
Instead, we're going for the more user-friendly approach of making a BASIC program that just calls our machine code. TOP is a BASIC variable with the address of the end of the current program, where we can stash our code, and CALL TOP will jump there. But since BASIC can load it anywhere[5] we need position-independent code, which the 6502 doesn't exactly excel at. Happily, we can find our current address by calling a subroutine and looking in the stack debris for the address that the CPU pushed and subsequently returned to. PAGE is 256-byte aligned (hence the name) so we only need the high byte, and from there we can construct a loop to copy ourselves to a known address and resume from there.
What subroutine do we call? We can't call any of our own code (because we don't know where it is yet) so that leaves OS API calls. We ask the OS to acknowledge an escape condition, which turns off the beep begun when loading finished. Since we're about to disable interrupts the OS will never have the chance to unbeep otherwise.
.basic
0500 0D ; start of BASIC line
0501 07 E3 ; line number &7E3 = 2019
0503 07 ; line length
0504 D6 ; token for CALL
0505 B8 ; token for TO
0506 50 ; ascii P
0507 0D ; start of BASIC line
0508 FF ; end of program marker
.reloc
0509 38 SEC ; execution starts here
050A 66 FF ROR &FF ; set top bit of &FF (escape flag)
050C A9 7E LDA #&7E
050E 20 F4 FF JSR &FFF4 ; OSBYTE 126
0511 A0 00 LDY #&00 ;
0513 84 B9 STY &B9 ; zero low byte of pointer
0515 BA TSX
0516 BD 00 01 LDA &0100,X ; get high byte of PC from stack
0519 85 BA STA &BA ; and store into high byte of pointer
.relocloop
051B B1 B9 LDA (&B9),Y ; copy byte
051D 99 00 05 STA &0500,Y
0520 C8 INY
0521 D0 F8 BNE relocloop
0523 4C 26 05 JMP main
Then we turn the tape back on, clear the screen and print the empty progress bar.
.main ; main code starts here
0526 78 SEI
0527 A9 85 LDA #&85
0529 8D 10 FE STA &FE10
052C A9 D5 LDA #&D5
052E 8D 08 FE STA &FE08 ; turn tape on
0531 A0 0A LDY #vduend-vdutab
0533 84 9F STY progress_count
.vduloop
0535 B9 6B 05 LDA vdutab,Y ; fetch character
0538 20 CB FF JSR nvwrch ; and print it
053B 88 DEY
053C 10 F7 BPL vduloop ; loop until done
[...]
.vdutab ; string to be printed. read backwards!
056B 5B ; print "[". cursor left in place for further printing
056C 1F 11 1F ; move cursor to (17,31)
056F 5D ; print "]"
0570 1F 3E 1F ; move cursor to (62,31)
0573 00 16 ; set screen mode 0 (80x32 characters)
.vduend
Now, this takes some explaining. Portable tape recorders in the 1980s typically had a remote input whereby recording or playback could be paused by a remote switch, often on an external microphone. Computers used this to enable the tape motor iff they were expecting to read or write data. This was useful to prevent users having to remember to stop the tape themselves or risk losing their tape position or even erasing the entire rest of the tape by accident.
Obviously playback from a device without such a remote control (such as the audio output from almost any other device, be it a laptop, phone, stereo, &c.) would end up with the audio continuing after loading finished with no means for the computer to stop it. But emulators all implement remote control for their virtual tapes. Since clearing the screen takes a non-negligible amount of time, and this code was developed on an emulator with remote control but was intended to be played back to real hardware from a device without remote control, we turn the tape on immediately so that calibrating how long a delay would be necessary while the CPU was busy clearing is possible without needing to test on real hardware.
Interlude: clearing the screen
We're using the high-resolution monochrome screen mode for the logo, which is 20K of data to clear. How does the clearing happen? The screen memory is located from &3000 to &8000, and we want to set it all to a given byte. The obvious way is the following 6502 code:
2000 A2 30 LDX #&30 ; start from &3000
2002 8E 09 20 STX clearloop+2 ; changes instruction below to "STA &3000,X"
2005 A2 00 LDX #0
.clearloop
2007 9D 00 EE STA &EE00,X ; EE gets overwritten
200A E8 INX
200B D0 FA BNE clearloop
200D EE 09 20 INC clearloop+2 ; increment high byte
2010 10 F5 BPL clearloop ; loop while it's less than &80
2012 60 RTS
This weighs in at 19 bytes and ~205k clock cycles, or about 100 milliseconds on a 2MHz processor. (It's also self-modifying, which rules it out for inclusion in ROM. Self-modifying code is common on 6502-based systems: it's often both faster and smaller than the alternatives.)
Instead, the Beeb has the following loop, unrolled an astounding eighty times and reproduced here in its entirety:
cc02 9d 00 30 sta $3000,x ; store byte to &3000+X
cc05 9d 00 31 sta $3100,x ; ...
cc08 9d 00 32 sta $3200,x
cc0b 9d 00 33 sta $3300,x
cc0e 9d 00 34 sta $3400,x
cc11 9d 00 35 sta $3500,x
cc14 9d 00 36 sta $3600,x
cc17 9d 00 37 sta $3700,x
cc1a 9d 00 38 sta $3800,x
cc1d 9d 00 39 sta $3900,x
cc20 9d 00 3a sta $3a00,x
cc23 9d 00 3b sta $3b00,x
cc26 9d 00 3c sta $3c00,x
cc29 9d 00 3d sta $3d00,x
cc2c 9d 00 3e sta $3e00,x
cc2f 9d 00 3f sta $3f00,x
cc32 9d 00 40 sta $4000,x
cc35 9d 00 41 sta $4100,x
cc38 9d 00 42 sta $4200,x
cc3b 9d 00 43 sta $4300,x
cc3e 9d 00 44 sta $4400,x
cc41 9d 00 45 sta $4500,x
cc44 9d 00 46 sta $4600,x
cc47 9d 00 47 sta $4700,x
cc4a 9d 00 48 sta $4800,x
cc4d 9d 00 49 sta $4900,x
cc50 9d 00 4a sta $4a00,x
cc53 9d 00 4b sta $4b00,x
cc56 9d 00 4c sta $4c00,x
cc59 9d 00 4d sta $4d00,x
cc5c 9d 00 4e sta $4e00,x
cc5f 9d 00 4f sta $4f00,x
cc62 9d 00 50 sta $5000,x
cc65 9d 00 51 sta $5100,x
cc68 9d 00 52 sta $5200,x
cc6b 9d 00 53 sta $5300,x
cc6e 9d 00 54 sta $5400,x
cc71 9d 00 55 sta $5500,x
cc74 9d 00 56 sta $5600,x
cc77 9d 00 57 sta $5700,x
cc7a 9d 00 58 sta $5800,x
cc7d 9d 00 59 sta $5900,x
cc80 9d 00 5a sta $5a00,x
cc83 9d 00 5b sta $5b00,x
cc86 9d 00 5c sta $5c00,x
cc89 9d 00 5d sta $5d00,x
cc8c 9d 00 5e sta $5e00,x
cc8f 9d 00 5f sta $5f00,x
cc92 9d 00 60 sta $6000,x
cc95 9d 00 61 sta $6100,x
cc98 9d 00 62 sta $6200,x
cc9b 9d 00 63 sta $6300,x
cc9e 9d 00 64 sta $6400,x
cca1 9d 00 65 sta $6500,x
cca4 9d 00 66 sta $6600,x
cca7 9d 00 67 sta $6700,x
ccaa 9d 00 68 sta $6800,x
ccad 9d 00 69 sta $6900,x
ccb0 9d 00 6a sta $6a00,x
ccb3 9d 00 6b sta $6b00,x
ccb6 9d 00 6c sta $6c00,x
ccb9 9d 00 6d sta $6d00,x
ccbc 9d 00 6e sta $6e00,x
ccbf 9d 00 6f sta $6f00,x
ccc2 9d 00 70 sta $7000,x
ccc5 9d 00 71 sta $7100,x
ccc8 9d 00 72 sta $7200,x
cccb 9d 00 73 sta $7300,x
ccce 9d 00 74 sta $7400,x
ccd1 9d 00 75 sta $7500,x
ccd4 9d 00 76 sta $7600,x
ccd7 9d 00 77 sta $7700,x
ccda 9d 00 78 sta $7800,x
ccdd 9d 00 79 sta $7900,x
cce0 9d 00 7a sta $7a00,x
cce3 9d 00 7b sta $7b00,x
cce6 9d 00 7c sta $7c00,x
cce9 9d 00 7d sta $7d00,x
ccec 9d 00 7e sta $7e00,x
ccef 9d 00 7f sta $7f00,x
ccf2 e8 inx ; increment X
ccf3 f0 70 beq exit ; and branch if it wraps around to zero
ccf5 6c 5d 03 jmp ($035d) ; loop again
[...]
cd65 exit:
cd65 60 rts ; return
This takes about 105k cycles, which is almost twice the speed of the first routine. The downside is that it's over ten times the size at 246 bytes, and that's excluding the initialization code (not shown) that sets up the jump vector at &035D.[6]
To put this in perspective: the BBC Micro's operating system is 15616 bytes (16K minus three pages for memory-mapped I/O). Thus over 1.5% of the OS is devoted to making clearing the screen fast.
This code has another interesting characteristic, namely that it clears the screen nonlinearly. Addresses ending in &00 are cleared first, followed by addresses ending in &01, and so on. This is easily demonstrated with the following program:
10 MODE 1 320x256 graphics, four colours (20K screen memory)
20 *FX16
30 *FX151,70,64 slow down the machine so we can see what's happening
40 *FX151,69,1
50 *FX11 disable autorepeat so we can still type afterwards
60 COLOUR 135:CLS clear to white and black alternately
70 COLOUR 128:CLS
80 GOTO 60
Eighty STAs gives eighty starting points. Hold down a key to pause.[7]
Also demonstrated is the odd screen memory layout, a consequence of the Beeb's use of the character-oriented Motorola MC6845 address generator chip.[8] Each character line is 8 pixels high. Acorn's later Archimedes machines ditched this layout for a linear framebuffer, which is now universal.
The BBC Master had a different, more conventional screen clearing routine (again some initialization omitted):
cb9a loop:
cb9a 91 d8 sta ($d8),y ; write a byte to screen pointer at D8-D9
cb9c c8 iny ; and increment
cb9d 91 d8 sta ($d8),y ; write another byte (2x unrolled loop)
cb9f c8 iny ; and increment
cba0 d0 f8 bne loop ; loop if low byte hasn't wrapped to zero
cba2 e6 d9 inc $d9 ; increment high byte of pointer
cba4 ca dex ; decrement high byte of counter
cba5 10 f3 bpl loop ; and loop if still >=0
cba7 60 rts ; return
Smaller and more flexible than the original Beeb's, this code nonetheless loses some of the blazing speed, taking about 195k cycles—about as fast as the self-modifying version.
Stage 2: load the decompressor
After the OS has cleared the screen for us we repeatedly call a routine to wait for and return a byte read from tape.
This routine does a couple of other things, as it will be called by other code further down the line. Every 35th byte read it prints a # (also ASCII 35: reusing the constant results in slightly smaller code, and we can adjust the length of the progress bar so that the number of bytes we have to read fills it up exactly). It also checks a flag to see whether the music has been loaded yet, and if so interleaves checking the tape with polling the music player. To avoid having to explicitly initialise the flag we reuse a location that we had to set to zero as part of the earlier relocation loop.
.loadinitial
053E 20 4D 05 JSR get_crunched_byte
0541 99 00 04 STA &0400,Y ; read decompressor
0544 88 DEY
0545 D0 F7 BNE loadinitial
0547 20 1E 04 JSR decrunch ; decompress music player
054A 4C 09 28 JMP runner ; and jump to it
.get_crunched_byte ; read byte from tape
054D 08 PHP
054E C6 9F DEC progress_count
0550 D0 07 BNE poll_things
0552 A9 23 LDA #&23 ; '#'
.nop_this_out
0554 20 CB FF JSR nvwrch ; this gets modified later
0557 85 9F STA progress_count
.poll_things
0559 A5 B9 LDA music_loaded
055B F0 03 BEQ nomusic
055D 20 9F 27 JSR poll ; poll the music player
.nomusic
0560 AD 08 FE LDA &FE08 ; check for byte from tape
0563 4A LSR A
0564 90 F3 BCC poll_things ; no? repeat
0566 AD 09 FE LDA &FE09 ; yes? return byte read
0569 28 PLP
056A 60 RTS
In total we read 255 bytes from tape (hence only needing a single 8-bit register as a counter) and store them verbatim (albeit backwards; another space-saving measure). This is our decompression code. Then we jump there.
Milestones achieved: our progress bar is about a fifth of the way along. Not much to see.
Stage 3: decompressing the music player
The decompressor is the wonderful Exomizer. This uses an LZ77-based algorithm that, when given a stream of bytes, will decompress to a buffer in memory. The target location is stored at the beginning of the data stream, and decompression is self-terminating (i.e. it knows when it's done without needing to be told explicitly). Exo has other modes of operation such as outputting a byte stream which need extra temporary storage, but in our case no other buffers are needed for the decompression other than 3 52-byte tables.
We locate the tables in zero page, which is faster and takes less code to address than elsewhere in memory. This brings our total decompression code size down to 258 bytes. So close! Another 3-byte table (pre-initialized, hence usually part of the decompression code) can be moved elsewhere. But where? It could be part of the earlier data block, but instead we elect to make use of four "reserved" bytes in the block header, which is stored from &3B2-&3D0.[9] Now we're down to the 255 bytes mentioned previously.
Exo will call our "read a byte from tape" routine whenever it needs more data, and fill the output buffer from the end backwards. The music player is 2114 bytes, which compresses down to 1275 bytes, and will end up stored from &2000 to &2842.
1275+255 is 1530 bytes, which should take our progress bar all the way to the end. 1530/35 is 43.7, which means we want it to be 44 characters wide, which fits nicely on an 80-column screen.
Milestones: we're done with the progress bar.
Stage 4: decompressing the image
Since the logo is nearly square, we use a custom screen mode of 576×272 pixels. This has 16 pixels of vertical overscan but since most of the logo pixels at the top and bottom are near the centre this looks OK on a CRT with rounded corners. 576×272 at 1 bit per pixel is 19584 bytes, which is smaller than the 20480 bytes for the normal 640×256 screen. We keep screen memory at &3000, but since our framebuffer is smaller now the progress bar at the bottom is no longer within it and handily vanishes as soon as we reprogram the 6845.
We also turn shadow screen memory off, disabling the feature on later machines where the framebuffer could be paged out to leave more RAM for user applications.
We want to turn the progress bar off, so we patch the opcode within the much-abused "get byte from tape" routine of the call to print the #. Before we had JSR nvwrch (20 CB FF), which calls the OS-provided "write character to screen" routine. After, we have BIT nvwrch (2C CB FF), which does nothing useful other than change processor flags. (We save and restore the flags anyway as Exo doesn't like them changing out from under it.) Using BIT as a no-op this way was common in 6502 code where size was at a premium, and was used in Microsoft BASIC among other places.
We initialise the music player (whose workspace just so happens to overlap the "music loaded" flag...) and call Exomizer again to decompress the image. The image compresses quite well, from 19584 bytes to just 6225. Since exo decompresses backwards, it loads from the bottom up (leaving the all-important flag text till last).
Once we're done decompressing, we turn the tape off and just call the music player in a loop.
.runner
2809 A0 0A LDY #10
.regloop
280B 8C 00 FE STY &FE00 ; select 6845 register
280E B9 37 28 LDA regs-1,Y ; load value from table
2811 8D 01 FE STA &FE01 ; and send to the 6845
2814 88 DEY
2815 D0 F4 BNE regloop ; loop while >1
2817 A9 0F LDA #&0F
2819 8D 34 FE STA &FE34 ; turn off shadow RAM
281C A9 2C LDA #&2C ; opcode for BIT with 2-byte address
281E 8D 54 05 STA nop_this_out ; disable progress bar
2821 20 3E 27 JSR playinit ; initialize music player
2824 20 1E 04 JSR decrunch ; load image
2827 A9 45 LDA #&45
2829 8D 10 FE STA &FE10 ; turn off tape
.runloop
282C A9 40 LDA #&40
282E 2C 4D FE BIT &FE4D
2831 F0 F9 BEQ runloop ; wait for timer
2833 20 9F 27 JSR poll ; poll music player
2836 D0 F4 BNE runloop ; and loop (always)
.regs ; register table, 1-indexed
2838 48 ; 1: 72 horizontal characters displayed (=72*8=576 pixels)
2839 5E ; 2: 94 horizontal sync position
283A 28 ; 3: 40 horizontal sync width
283B 26 ; 4: 38+1=39 vertical character lines (=39*8=312 lines)
283C 00 ; 5: 0 vertical adjust
283D 22 ; 6: 34 vertical characters displayed (=34*8=272 pixels)
283E 24 ; 7: vertical sync position
283F 00 ; 8: interlace disabled
2840 07 ; 9: 7+1=8 max scanline address
2841 20 ; 10: disable cursor
Stage 5: the tune
The Beeb has a Texas Instruments SN76489AN Programmable Sound Generator (PSG) chip. It has 4 voices: 3 voices of 50%-duty-cycle square wave and 1 voice of noise generated by a 15-bit LFSR. Each voice can be independently attenuated by anywhere from 0 to 28dB in 2dB increments, or disabled entirely.
We set the system VIA timer 1 to run freely with a period of &6262 1MHz cycles, which is about 39.7Hz. Each time the timer expires we advance the music pointer by one event. Each event can have a new note or volume or both.
Events are chunked into "patterns" of 16 events each. Approximately ¾ of the patterns are duplicates, but each is only stored once. The list of patterns and the events themselves are lightly compressed using a custom run length encoding (RLE) scheme.
Patterns contain data for a single voice, and consist of a stream of alternating bytes. one for pitch (0-63, semitones) and one for volume (0-15 in units of 2dB attenuation, where 15 means "silent"; this is the 76489's internal volume register format[10]). &FF means "don't write anything". So, e.g. 4300 ff02 ff03 ff06 4100 ff02 has two notes at full volume at events 0 and 4, and they fade a bit afterwards.
All the pitch and volume values have the top bit clear, so the top bit is repurposed for RLE. Binary 0xxxxxxxx means byte x and 1xxxyyyy means xxx bytes of &FF (&FF means "empty", so occurs frequently). It would seem a shame to waste the four yyyy bits, so if yyyy is non-zero, yyyy means "output an extra byte 0000yyyy" after the run of &FFs. Zero is used a lot as a volume but some of the other values aren't, thus the volume is xored with a tweakable constant so that zero can be packed too. Pitches are also xored for similar reasons: if common pitches can be stored in four bits, they can potentially be tagged onto the end of an RLE run too. The noise voice simply has no pitches.
The sequence data consists of another stream of bytes, again per-voice. It contains two bytes of pointer-into-pattern-data for each sequence. But many patterns follow on from each other, so often the pattern data pointer would already be pointing to what we would just be about to load.
The pattern data is <2K, which is only 11 bits. There are 16 to play with, again leaving some spare for RLE. So, a single &FF byte means "don't bother loading anything", and if we shift the top bit of the low byte of the two-byte pointer into the high byte we can use the existing RLE code (recall that it can only output bytes with the top bit clear). The sequence pointers are stored straight after the voice pointers, and the RLE routine gets called with a voice number from 4-7 instead of 0-3 for the actual voices. Thus runs of adjacent patterns (such as the melody, which isn't very repetitive) get encoded as a single byte too. So we have 11111111 for nothing, 01xxxxxx 0yyyyyyy for a two-byte pointer, and 00zzzzzzz spare. The 6 zzzzzz bits we can use as a signed offset from the current pointer.
If zzzzzz fits in 4 bits, again we can use the tagging-onto-the-end-of-an-RLE-run scheme. The offset calculation is chosen carefully so that this happens often, which is why bit 6 is clear for a single-byte offset.
One final evil hack: when the melody cuts out at the end just before the loop, it's cheaper to compare the sequence position with that position and ignore the melody voice from then onwards than it is to store repeated pointers to an empty pattern.
The source XM is by my reclusive friend K circa 2008 and was written specifically with the 76489 in mind. I wrote the conversion script and Beeb playroutine (demoscene-speak for "an embeddable music player you can use in your demo") a few days later, and much of this explanation of it is cribbed from decade-old chat logs.
Postmortem
So how did people get on?
Before I do that, here is a Beeb configured similarly to the one at the conference should you like to try it yourself.
S
P
O
I
L
E
R
S
The BBC Master on display at the conference handily already had a 3.5mm audio jack plugged into the cassette port, to which was attached to an MP3 player in shuffle mode playing an image slideshow. So all people actually needed to do after plugging in their laptop was to switch filesystem to tape (from the default disc) and run the first program found. The former is canonically done with *TAPE (abbreviated *T., case-insensitive) but can also be accomplished by holding down T and pressing Break. The latter: CHAIN"" (abbreviated CH."", case-sensitive: run BASIC program). Most games and other software titles were originally supplied with these instructions. In our case *RUN (abbreviated */, case-insensitive: run machine code program) would also work.
Stairway to Hell is probably the best web reference that tells you this succinctly. (Their suggested PAGE=&E00 is redundant for us but necessary for some very early software predating disc systems that would otherwise run out of memory due to making assumptions about OSHWM that would later prove unwise.)
Instead the booby prize is chapter 35 of the User Guide, the original 1981 documentation supplied with the Beeb, which is the top google hit for "bbc micro load tape". This is... not the best document for figuring out how to do this, particularly if you're in a hurry because it's the middle of a conference.
I saw one group trying to work out what to do with this as their only guide. That was fun. Here's what they did (I egged them on only slightly):
- Type LOAD "PROG" without switching to tape first. This hangs as it waits for the non-existent disc drive to respond.
- Figure out *TAPE and type LOAD "PROG", not realising that PROG was merely an example filename and that such a command would result in any other file being catalogued but not loaded. To be fair, the User Guide does mention that it's only an example in the previous section devoted to saving files. Clearly the authors assumed that people would have nothing to load unless they'd saved it themselves (or that commercial software would be supplied with its own instructions).
-
Type LOAD "BeebSides", painstakingly typing in the filename listed as as result of the previous step, rather than using the common shortcut of a empty filename to mean "whatever you find next". This is not even mentioned as a possibility in the User Guide. (To be fair, this shortcut works only on tape and not on disc, which has no concept of "next").
-
Successfully load the BASIC program with LOAD, get a beep and prompt back, and be unsure what to do next.
- Figure out to type RUN to run the program but not consider that (a) the WAV file is about a minute long and loading the BASIC program took about a second, ergo (b) there was more data that it was expecting to load that had passed by while they were figuring and typing.[11]
- Watch it work anyway because I'd not asked the OS to clear memory contents on Break, so all the code was already in RAM from the previous guys who'd run it successfully...

At least one other person got it running but didn't recognise it as a flag before Mark revealed all at the end of the day. (In my defence, I've never participated in a CTF before so had only a single-sentence description of what flags typically look like.)
I also witnessed it fail in an unexpected manner when loaded correctly (screen didn't clear before printing the progress bar; bar progressed normally but it subsequently hung when about to load the image). Again I'm chalking this up to not having cleared the memory. Lesson learned.
Total number of successful flag captures: three (not counting Mark, who'd solved it a week or so earlier, as well as solving the (sadly) much more demanding challenge of getting the WAV file into an emulator).
[0] "Capture the flag" contests, typically involving some kind of hacking challenge that, when solved, reveals some text redeemable for points and/or prizes from the organizers, are a staple at security conferences.
[1] The block length field is 2 bytes. Does this mean you can have blocks longer than 256 bytes? No, no it does not.
[2] The CRC covers only the header. The actual data in the block has a separate CRC, following the data.
[3] Actually, for fascinating reasons I'm not gonna get into, it skips clearing every 256th byte of memory (those whose addresses end in &00). This was corrected on the BBC Master.
[4] E.g. http://www.acornelectron.co.uk/eug/71/h-lock.html. This is a classic time-of-check-to-time-of-use (TOCTOU) attack: only after the header is read in its entirety does the OS start to decode it. As it trickles in at 1200 baud, there's plenty of time to modify its contents before it's used simply by hooking the 50Hz vertical blanking interrupt.
[5] "OK, so maybe BASIC can load it anywhere, but surely there's a default load address that we can assume? Right?"
Unfortunately not. The default is the prettily-named OSHWM (OS high water mark), which varies depending on what expansions you have fitted. &E00 is the norm on cassette-based BBC Micros and Electrons, and all Masters, whereas &1900 is usual on BBC Micros with a disc system (i.e. most of them). Other, rarer values include &1D00 on Electron with Plus 3 fitted (the official disc system for the Electron, now with hierarchical filesystem!) or BBC Micro with same, &1F00 for BBC Micros or Electrons with support for both disc types, and &800 on a second processor. Add anywhere from &100 to &500 if you decide you want to define lots of character bitmaps. You get the idea.
[6] The point of the indirect jump is to allow changing the amount of screen memory cleared. While always ending at &8000, the screen starts at &3000 or &4000 or &5800 or &6000 or even &7C00 depending on video mode.
[7] The slowdown is achieved by changing the system VIA timer 1 frequency, normally 100Hz, to about 5kHz. The Beeb can barely cope with interrupts at this rate, and the extra processing required when a key is held down renders it completely stuck until the key is released.
[8] Datasheet, with registers, here. We will be needing these later.
[9] Specifically, they are reserved when storing files on tape but are used when storing files on a ROM cartridge (the OS code for which is largely shared with the tape loading code). These locations and more are documented at https://mdfs.net/Docs/Comp/BBC/AllMem.
[10] More details on register formats can be found in the 76489 datasheet. Note that the frequency of the square wave voices are controlled by a simple 10-bit counter, so we need a lookup table to convert from semitones. The table is only 12 entries long as an octave corresponds to dividing the counter period by two.
It may seem odd that we're doing this manually rather than using the OS's extensive sound facilities, but there's a good reason. Playing the same note on multiple voices simultaneously would result in the phase between voices remaining constant but undefined, producing unpredictable total volume or even complete silence if you were unlucky. Acorn went to remarkable trouble to avoid this counterintuitive behaviour being exposed to users: they added the voice number (0, 1 or 2) to the period register, thus detuning some notes slightly but ensuring that when playing multiple copies of the same note the phase was continuously varying, fixing the volume problem and making a fuller sound with a characteristic "beating".
Sadly, because the periods get closer together as notes get higher, the out-of-tune-ness becomes much more noticeable the higher you go. We can avoid playing several of the same note but sadly the workaround cannot be disabled, other than by bypassing the OS entirely.
[11] I considered having the tape loader check for some known bytes before blindly loading and executing whatever it read, but ultimately decided keeping it small was more important.
Applause
So a friend of mine tweeted about something that bothers him. It bothers me too, just in the opposite direction. Maybe finding someone with actual opinions on this is my chance to resolve something that's puzzled me my entire life.
Humans do a lot of things that baffle me. Applauding is one of them. In my world, if you go to see musicians perform, it is only polite to shut the hell up and not disrupt the experience for other audience members or interrupt the concentration of the performers. Optionally, you can show your appreciation afterwards using the bizarre but societally-approved method of repeatedly smashing your palms together1, but don't do it in the middle of a piece. If you're not sure if it's still the middle of the piece, err on the side of extreme caution to avoid making an ass of yourself. To my mind, even doing it immediately afterwards can ruin the moment. Me, I'd give it a good twenty seconds of silence first, particularly after a quiet ending.
It could of course be worse. It could be a rock concert, where clapping and whistling and screaming and making a general hullabaloo is considered SOP. And what do the organizers do? They turn the fucking volume up to compensate, to the point that earplugs are recommended accessories for frequent concert-goers. Do Not Want.
My conclusions have largely been "people are weird, film at eleven" and "avoid live music concerts, particularly rock concerts". Sadly this is insufficient, because live recordings are a thing. Audience noises do not add "atmosphere" to a recording, they just reduce the signal-to-noise and make it more annoying to listen to.2
Anyway, back to the tweet. "I let people applaud whenever they fucking wanted to in my concerts." To my mind this misses the point entirely. You can't prevent people from applauding! This is the whole problem! Trying to dissuade people beforehand would indeed almost certainly get you perceived as a stuck up wanker, and thus as a performer there is simply nothing you can do.
This is one of many reasons I don't give concerts. A minor one, admittedly, overshadowed by the fact that I suck and I have no idea how to find a venue or an audience3. Still, the possibility of being applauded at mid-musicking haunts me, because I know I would react badly.
Music is important. Don't ruin it by clapping. Please?
(I guess in addition to being a stuck up wanker I am also a contrarian windbag for not wanting to reply within 140^H^H^H280 characters.)
[1] I'd be delighted if people were to adopt the mould-friendly thumbs-up.
[2] Not to mention that, for a given amount of practice, it is much easier to make an accurate recording with modern editing technology than it is to make an accurate real-time performance. Mistakes do not add atmosphere either.
[3] There's also that one time when I was ~12 when I bowed to the wall because people assumed I knew what bowing was for. I didn't, and was confused when faithfully executing the macro I'd been given earned me a reprimand afterwards.
Memory mapping the TiLDA
Last time I looked at the TiLDA and how to make it run native code. Anyone who's played with this device for any length of time (read: five minutes) knows that there's a serious memory shortage. There's only 128K of RAM total and half of that's used by MicroPython. By the time your app is running you have perhaps 30K to play with.
It gets worse. Because the garbage collector can't move blocks around, the heap gets fragmented incredibly quickly. You want to load a 10K file? Nope. 5K? On a good day.
Here gc.mem_free() is reporting 30944 bytes free, which is technically correct (the best kind of correct!), but pyb.info(1) reveals the true story. Each line is one kilobyte, and free space is represented by dots:
GC memory layout; from 20003c80:
00000: MDhhhhBLhhDh======BBBhh=============h=ShSh=ShSh=Sh=BhBBhBB=BBBBh
00400: =====h=======h=====BTh===BhDBhhh=B=h============================
00800: ====================================================h========h==
00c00: ===BBBB=hB=BhBhBhBBhShBhBhBhhBh=BhSBhSSB=BBSh===B=hSB=hB=h=B=BBB
01000: Sh========Bh=BBhhhShShhShSDh=hShSFhShFShSFh=hLhShh=ShhBSh===hSSh
01400: ===========hShShh=====ShShShShDh=ShLhSShShShShShShShShShShShShSh
01800: Sh=========================h==Sh==Sh=Sh=Sh=h====================
01c00: h==ShShShShShShh=hh=hh===hh=hh============h=Sh====ShShShShSh=h==
02000: hh==hh=hh==============h=Sh====ShShShShSh=h======hSh=Sh=h=hh=hh=
02400: ===================================hShh=h=h=h=hShShShShShShSh=hh
02800: hShShShShSh=h=Bh=hhBh=hBhhh=hBhShSh=hhShSh=hShShShShShShShShShSh
02c00: ShShShShShhhh=====hShShShShShShShShShShShShShShShShSh=hBhhBh....
03000: ...h=....h=.....................................................
(2 lines all free)
03c00: ...................h........MD..................................
(6 lines all free)
05800: ............................................MD.h=...............
05c00: .BD..B.B=BB.B..B=Bh===B=h====B..h===.BBBBh=======.........h=====
06000: =====B.B=.SMD.h=======.DDF.Bh=====....MD.BBB....MD...MDF........
06400: ...hSFFhh.hhhh...hh.....h.Bh=======h.B=B.......BDDBhh=======h===
06800: ===..hh..hh.h===hh..B=B.Bh=======h=======B=............h==hh====
06c00: ===.....h========B=BBBBM......h======h============hh============
07000: ============================h=======h=hh=======h=======h========
07400: ===M.h==h==hh=======hSh===h==hh==hh==hh=====hh=hh=hD..D.Mh=.....
07800: DBB..Lhh=======h.h=====B...hBh=D...Bh=.BBB.....h===========..h==
07c00: =====BB.....B=B....Sh..h=hhShh=====h=====h========h==S.......BMB
08000: D.h=S.....h=======h====================h========...............h
08400: ===.......h==hSh==.......h==============hh==hh===.h=..........h=
08800: ========.............h=======h====h====h==h.h=======h===h=B==...
08c00: ........B==.B==..................h====h====h====h=======h=....h=
09000: =h============h==h=====h==hh======.h==h=h=hF............B==DB..h
09400: S....MDB=.BB....hBBh===h===.....hSh=h=h=====...h========.h======
09800: =h==hShFh========....hh.........................................
09c00: ........h....................................h===hShh=........h=
0a000: h==h====h===h===================================================
0a400: ==...h========h=====h===========h=h=Sh=======h==========hhS..h==
0a800: ==.....................................................h=======.
(2 lines all free)
0b400: ..............................................Sh=======.........
0b800: ................................................................
0bc00: h================hh===========h=h=======h=hh==h=================
0c000: ================================================================
0c400: ================================h==Sh=ShSh===Sh==Sh=ShShSh===h==
0c800: =hShSh....h.......h...................................Sh........
0cc00: ................................................................
0d000: ....................................h=======....................
0d400: ................................................................
0d800: ..................................h...................h=========
0dc00: ===================================================.............
0e000: .................................hh.............................
0e400: h=======.....h..................................................
0e800: ..............h===h====h==hh=====hSh==h==hh==hh=====hh==h======h
0ec00: h=hh=hh==hh===hh==hh==hh==hh===hh==hh========hh==hh=====hSh==h=h
0f000: h=hh===hh==hh==h................................................
0f400: ................................................................
0f800: ...........h==h===h=h===========================h=h=============
0fc00: ========================h=h==================================h=.
10000: .......h================hh===hh=hh=hh=hh=hh==h.h=h=.....
We'd be lucky to find 2K of contiguous memory free! Once you start delving into nativity, how objects are laid out in memory starts to become really important. Last time's app was reduced with a bit of effort to 3200 bytes (from about twice that), but they still need to be consecutive bytes. Writing anything bigger would be a problem. In particular graphics take up an awful lot of space.
FAT
But stepping back a moment. The data we want is already stored in the filesystem. The filesystem is in flash. Flash is memory-mapped. Furthermore, the filesystem is FAT, which is primitive and doesn't have any annoying gotchas such as compression. So the data we want should be there for the taking.
The FAT implementation in micropython is a generic device-independent filesystem. It can use filesystems stored anywhere (e.g. on an SD card), for any device for which a "get block" and optionally "put block" function are provided. It assumes that block reads and writes are slow and will cache blocks in RAM when it thinks this is useful. For the case of our flash filesystem, this means a lot of unnecessary block copies and memory usage. There is of course no mmap() function, and it's not even clear how the filesystem could usefully provide one with the existing block device API.
But maybe we can make our own.
Thus the following idea. Open a file and read its contents. Loop through the entire flash (it's only a megabyte) looking for where it's stored. The cluster size is 512 bytes, so files will start on a 512-byte boundary.
def mmap(file):
buf=bytearray(open(file).read())
for ptr in range(0x8000000,0x8100000,512):
## it'd be so great if this worked
#if stm.mem8[ptr:ptr+len(buf)]==buf:
# return ptr
for i in range(len(buf)):
if stm.mem8[ptr+i]!=buf[i]:
break
else:
return ptr
Because of the previously-mentioned limitations of the stm.mem* functions we have to iterate by hand rather than using slices, which is hideously slow. But we can of course write a native version1:
def mmap(file):
@micropython.asm_thumb
def findblk(r0,r1,r2):
data(2,0xf500,0x7000,0xf1b0,0x6f01,0xd208,0x2300,0x58c4,0x58cd)
data(2,0x42ac,0xd1f5,0x3304,0x4293,0xd1f8,0xe000,0x2000)
buf=open(file).read()
return findblk(1<<27,buf,len(buf))
There are complications. Firstly, filesystems suffer fragmentation just as the heap does, so files may not be contiguous either. Secondly, reading the entire file contents takes up the same amount of RAM, temporarily, as the file size. The second problem could be solved by only reading and comparing small chunks of the file at a time, but then either we require that the first chunk of the file uniquely identifies it, or we're willing to backtrack (possibly multiple times!) if we found a false positive early on in the search. Also possible is precomputing a hash for the file rather than actually reading it in (we wouldn't need to bother with filenames at all!), but then we'd need to pick an algorithm, and implement it, and hope there are no collisions... Messy, all told.
The first is the biggie though, and there's no easy solution. But we can mitigate both problems simultaneously by simply having small files, but lots of them—say, one per sprite. This turns out to work beautifully in practice.
Is it hacky? Why yes. But this is a microcontroller. If you're not prepared to get your hands dirty you're doing it wrong!
Next time: let's put mmap to good use by writing a game.
[1] There are a couple of gotchas with this code. Word comparisons are used, so ensure your files are a multiple of four bytes long. It takes an address to start searching at, but the first block is skipped. Here's the actual code encoded in the hex constants:
0: f500 7000 add.w r0, r0, #512 ; 0x200
4: f1b0 6f01 cmp.w r0, #135266304 ; 0x8100000
8: d208 bcs.n 0x1c
a: 2300 movs r3, #0
c: 58c4 ldr r4, [r0, r3]
e: 58cd ldr r5, [r1, r3]
10: 42ac cmp r4, r5
12: d1f5 bne.n 0x0
14: 3304 adds r3, #4
16: 4293 cmp r3, r2
18: d1f8 bne.n 0xc
1a: e000 b.n 0x1e
1c: 2000 movs r0, #0
TiLDA March: how to run native code from MicroPython
Another EMF, another badge! This one is the TiLDA MK3, an STM32-based board running MicroPython. It's similar enough to the pyboard that most of the following might be of use even to non-EMF attendees.
The MK3 is very much an embedded platform, with 128K of RAM, 1MByte of flash and an 80MHz Cortex-M4. How do you get performance out of such a device? Not by writing python, that's for sure.
We have two requirements for running native code. We need to be able to load code at a known address, and we need to be able to branch to it. The built-in assembler is terrible. It only supports a subset of instructions (and in a non-standard format, too). Nonetheless it has a data() function to insert arbitrary bytes into the instruction stream. Problem solved! Just write a script to convert gcc output into a series of data() calls and we're done. Right?
@micropython.asm_thumb
def arbitrary_code():
data(4,0x11111111,0x22222222,0x33333333...)
This works. But it's kind of inefficient, and since we have so little space it would be foolish to incur a 300% bloat penalty1. But it is enough to investigate the environment in which we find ourselves.
Addresses
Here's a useful function. It doesn't do anything itself.2 But nonetheless you can pass arbitrary python objects to it and get their addresses back.
@micropython.asm_thumb
def addr(r0):
mov(r0,r0)
We also have stm.mem* which lets us read and write arbitrary memory locations from Python. So we can build ourselves a hex dumper:
def dump(addr):
# copy memory just in case it changes out from under us3
a = bytearray(16)
for i in range(16):
a[i] = stm.mem8[addr+i]
out = "%08x: " % addr
for b in a:
out = out + ("%02x " % b)
for b in a:
out = out + (("%c" % b) if b > 31 and b < 127 else ".")
print(out)
addr(addr) returns its own address, which turns out to be some kind of struct with a pointer to the code at offset 8.
>>> dump(addr(addr))
20004a10: 4c fb 06 08 01 00 00 00 70 9f 00 20 02 00 00 00 L.......p.. ....
>>> dump(stm.mem32[addr(addr)+8])
20009f70: f2 b5 00 46 f2 bd 00 00 00 00 00 00 00 00 00 00 ...F............
Disassemble the code and we get to see the prologue and epilogue:
$ perl -e 'print chr hex for @ARGV' f2 b5 00 46 f2 bd >/tmp/dump
$ arm-none-eabi-objdump -b binary -m arm -M force-thumb,reg-names-std -D /tmp/dump
[...]
0: b5f2 push {r1, r4, r5, r6, r7, lr}
2: 4600 mov r0, r0
4: bdf2 pop {r1, r4, r5, r6, r7, pc}
Which looks fairly standard.
The goal though is to be able to get the address of a buffer that contains code we want to run. It turns out that python bytearrays are passed directly to assembly functions. Handy.
>>> test = bytearray([0x2a,0x20,0x70,0x47]) # "movs r0, #42; bx lr"
>>> dump(addr(test))
2000f950: 2a 20 70 47 00 00 00 00 00 00 00 00 00 00 00 00 * pG............
Now we can read a buffer from file and branch to it. So, assuming we would actually like to return control to python afterwards, how do we do the branching?
blx is the standard way to jump to an address and return afterwards. blx requires the instruction set (ARM or Thumb) to be encoded in the LSB of the address; while the Cortex-M4 supports only Thumb mode, the processor does indeed verify that this is the case, so we must set the LSB correctly or Bad Things happen.4 Sadly the older bl instruction (which doesn't change instruction set) can't branch to an address in a register. We could always push the return address ourselves and load the PC directly, but then we'd have to set the LSB on the return address!
The assembler refuses to assemble blx(r0) so we have to do it ourselves.
@micropython.asm_thumb
def call(r0):
data(2,0x4780) # blx r0
Then we can call code in our test buffer.
>>> assert(not(addr(test)&3)) # ensure the buffer is aligned
>>> call(addr(test)+1) # set the LSB and branch
42
Yes!
Of course, if we do the incrementing from within the call function we can dispense with addresses entirely:
def call_inc(r0):
data(2,0x3001,0x4780) # adds r0,#1; blx r0
buf = open("code").read()
call_inc(buf) # assumes buf is word-aligned, which seems to always be the case
Now to get gcc on board.
To C
Here's “hello world” without the hello (or the world).
$ cat test.c
int test(void) {
return 42;
}
$ arm-none-eabi-gcc -mthumb -mcpu=cortex-m4 -ffreestanding -nostdlib -fPIC test.c -o test
ld: warning: cannot find entry symbol _start; defaulting to 0000000000008000
$ arm-none-eabi-objcopy play -O binary test-raw
(Why not just get gcc to output a flat binary directly?
$ arm-none-eabi-gcc -Wl,--oformat=binary -mthumb -mcpu=cortex-m4 -ffreestanding -nostdlib -fPIC test.c -o test
ld: error: Cannot change output format whilst linking ARM binaries.
Apparently this is deliberate. I have no idea why.)
Let's have a look at the result:
$ arm-none-eabi-objdump -b binary -m arm -M force-thumb,reg-names-std -D test-raw
[...]
0: b480 push {r7}
2: af00 add r7, sp, #0
4: 232a movs r3, #42 ; 0x2a
6: 4618 mov r0, r3
8: 46bd mov sp, r7
a: f85d 7b04 ldr.w r7, [sp], #4
e: 4770 bx lr
A bit verbose perhaps, but we didn't ask for any optimization. Try it:
>>> f = open("test-raw")
>>> test2 = f.read()
>>> f.close()
>>> call_inc(test2)
42
Looking good. Things go badly very quickly though:
$ cat count.c
int arr[] = { 1, 2, 3, 4, 5 };
int count(void) {
int i, total=0;
for(i=0; i<5; i++) {
total += arr[i];
}
return total;
}
$ arm-none-eabi-gcc -Wall -mthumb -mcpu=cortex-m4 -ffreestanding -nostdlib -fPIC count.c -o count
ld: warning: cannot find entry symbol _start; defaulting to 0000000000008000
$ arm-none-eabi-objcopy count -O binary count-raw
Again we compile without optimization, in this case to avoid gcc simply returning a constant instead of performing calculations at runtime.
Suddenly our binary is 64K in size! And it contains some code that will never work:
$ arm-none-eabi-objdump -b binary -m arm -M force-thumb,reg-names-std -D count-raw
[...]
0: b480 push {r7}
2: b083 sub sp, #12
4: af00 add r7, sp, #0
6: 4a0e ldr r2, [pc, #56] ; (0x40)
8: 447a add r2, pc
[...]
14: 4b0b ldr r3, [pc, #44] ; (0x44)
16: 58d3 ldr r3, [r2, r3]
[...]
40: 003c movs r4, r7
42: 0001 movs r1, r0
44: 000c movs r4, r1
[...]
10054: 8058 strh r0, [r3, #2]
10056: 0001 movs r1, r0
Here it is trying to set R2 to the contents of PC+0x10054, which is 0x18058, and later reading from that address. Disassembling the original ELF output reveals what's going on: ldr r2, [pc, #56]: add r2, pc is attempting to load the global offset table. GCC has assumed (despite -ffreestanding!) that we're running in an environment with virtual memory where code and data are held in separate pages.
We need to create a custom linker script to tell it to not do that. Not being any kind of ld expert, here's what I cribbed together:
$ cat linkscr
SECTIONS
{
.text 0 : AT(0) {
code = .;
*(.text.startup)
*(.text)
*(.rodata)
*(.data)
}
}
108 bytes, plus our warning has gone away! That's more like it. We also need to replace -fPIC with -fPIE. The tempting -mpic-data-is-text-relative option is, happily, already enabled by default in gcc 4.8 and up.
$ arm-none-eabi-gcc -Tlinkscr -Wall -mthumb -mcpu=cortex-m4 -nostdlib -fPIE count.c -o count
$ arm-none-eabi-objcopy count -O binary count-raw
>>> call_inc(open("count-raw").read())
15
Awesome.
So having got this far I made a little app, a quick-and-dirty port of some existing C code I've been working on.
What's the code? And why is it so arcane? That's a story for another day.
Code is on github.
[1] 4 bytes written in hex is 0x12345678, (11 bytes). This will allocate another four bytes for the result, for a total of 15 bytes. Then there's the space for data() (which almost certainly has a limit on the number of parameters, so multiple statements would be required). Result: about four times the space.
[2] Indeed, we only need the no-op at all to avoid confusing Python with an empty function body.
[3] Sadly the implementation of stm.mem* contains the following line:
// TODO support slice index to read/write multiple values at once
so this somewhat unpythonic code is actually the best we can do.
[4] Bad Things include but are not limited to: LEDs flashing ominously, unresponsiveness (necessitating a reboot), filesystem corruption (necessitating a reinstall, with loss of data), and nasal demons.
Rainbow Noise
A friend of mine (hi K!) revealed to me recently that he uses a "background noise" app, and that he had some strange observations. He could hear patterns in the noise, right at the edge of audibility.
I was skeptical. Humans are notorious for imagining patterns everywhere: it's how we're wired. What other explanations could there be, if he wasn't just making it up?1 Perhaps the app was using a poor random number generator? Not exactly: further investigation revealed the surprising fact that the patterns seemed periodic—every 30 seconds to be precise—and it wasn't long from there until the discovery that yes, the app simply uses prerecorded segments of noise, and yes, they're exactly 30 seconds long.
This both astounded and disturbed me. That someone could detect long-range periodicity in randomness by ear was pretty neat. That someone would make an app that explicitly stored 5 megabytes of random data and played it back in a loop instead of writing a dozen lines of code was just depressing2, especially as it defeated the entire point (the supposed soothing properties of the noise were demonstrably being eroded by distracting patterns).
 Since the app offered various colours of
noise I found myself idly wondering how to
generate them algorithmically, then idly playing about, and before
I'd quite realised what I was doing I'd somehow written an app of my own.
Since the app offered various colours of
noise I found myself idly wondering how to
generate them algorithmically, then idly playing about, and before
I'd quite realised what I was doing I'd somehow written an app of my own.
Rainbow Noise offers six varieties of mathematically-well-defined noise. It also contains an easter egg. More accurately, it is an easter egg that just happens to contain a noise generator. Since bloating a simple app by over an order of magnitude just for the lulz is crazy (not to mention that unnecessary bloat was one of the motivating factors behind this in the first place), I have gone to some effort to keep the size down.3
Sadly the egg does not yet work in Chrome. Given the pathological loathing of legally-unencumbered codecs apparently shared by Apple and Microsoft, it doesn't work in Safari or IE either, but at least Google has acknowledged the problem. So maybe hooray for Google but definitely hooray for Firefox, where everything just works. (Why no, I will not be working around this bug.)
Code is on github.
[1] Presumably subconsciously, but you never know.
[2] Apparently randomness as a service is a thing these days. The notion that entropy is sufficiently hard to come by that you would ever need to look to a third party to provide you with some—and any would-be cryptographers who think this is a good idea should be beaten to death with their own S-boxes—is one of the dafter things I've ever heard. But not, perhaps, as daft as having a fixed entropy pool and outputting it verbatim over and over again.
[3] Not all-out. Some.
On Google Analytics
On the web, the "traditional" method of visitor tracking is at the origin web server. This is perfectly reliable and trustworthy: it is impossible to visit a site without contacting the origin server1, and no other parties need be involved. Tools such as webalizer perform logfile analysis and produce visitor statistics.2
However, in the past decade a new model of visitor tracking has achieved prominence: third-party tracking via javascript, often with a fallback to transparent 1x1 GIFs ("web bugs"). This model is exemplified by the most widespread tracking tool, Google Analytics.
Google Analytics (GA) is overwhelmingly popular. At the time of writing, approximately half of the web uses GA.3 There is no user benefit to participating in GA tracking, but there are costs both in resource usage and in information leakage. As a consequence, google-analytics.com is also one of the most blacklisted domains on the web.
How blacklisted? Here is a sampling of popular ad-blocking and other privacy-centric browser addons, along with their approximate userbase.
- AdBlock: over 40 million users (Chrome).
- Adblock Plus: 20,320,308 users (Firefox).
- Adblock Edge 731,135 users (Firefox).
- NoScript: 2,171,006 users (Firefox), plus every installation of Tor Browser (estimated 2 million daily users).
- Ghostery: 1,278,423 users (Firefox), 1,431,362 users (Chrome).
All of the above tools block GA by default. This is not counting other, more niche tools, or the individuals and organisations who block GA manually in their browsers or at their firewalls.
This is not a negligible number of people. Notwithstanding the fact that an awful lot of people seem to not want GA to be a part of their browsing experience, these are all people who will be invisible to GA, and absent in the data it provides. That it is possible (and even desirable) to opt out of third-party tracking undermines the entire concept of third-party tracking.
That Google offers such a deeply flawed service is easy to understand. The question for Google is not whether the data it collects from GA is complete, but whether it gets to collect it at all. Google is the biggest infovore in history: of course websites outsourcing their tracking to Google is a win for Google.
And yet, in part because it is easy to use, GA is incredibly widespread. Given its popularity, GA would perhaps seem to be a win for site operators too. I think not, and here's why: deploying GA sends a message. If a site uses GA, it seems reasonable to conclude the following about the site operator:
- You care about visitor statistics, but not enough to ensure that they are actually accurate (by doing them yourself).4 Perhaps you don't understand the technology involved, or perhaps you value convenience more than correctness. Neither bodes well.
- Furthermore, you're willing to violate visitors' privacy by instructing their browsers to inform Google every time they visit your site. Since in return you get only some questionable statistics, it seems visitors' privacy is not important to you.
If you run a website, this is probably not the message you want to be sending.
[1] The increasing use of CDNs to serve high-bandwidth assets such as images and videos does not change the fact that 100% of visits to a modern, dynamic site pass through the origin server(s). Frontend caches such as Varnish merely change the location of logs, not their contents or veracity.
[2] There are very probably more modern server-side tools available nowadays; I've been out of this game for a while now. Certainly CLF leaves a lot to be desired. But since web servers have all the data available to them this is strictly a quality-of-implementation issue.
[3] http://w3techs.com/technologies/overview/traffic_analysis/all claims 49.9%. http://trends.builtwith.com/analytics/Google-Analytics confirms this number, and offers a breakdown by site popularity. Of the most popular 10,000, 100,000 and 1,000,000 sites, the proportion using GA rises from 45% of the top million to nearly 60% of the top ten thousand.
[4] This is an assumption. Deploying GA does not preclude the option of tracking visitors at your web server. But since web server tracking is strictly better than GA, why would anyone bother to use both?
What's wrong with Threes 1
A few weeks ago, when the 2048 craze was at its height, this Mobile Mavericks article (mirror) was posted on HN. (Go read it. Go read it now. I'll wait.)
To say I disagree with this article would be putting it mildly. But hey, someone is wrong on the internet. It happens all the time.
However, here's the Threes team weighing in on the topic. They say essentially the same thing, only more diplomatically: woo, something we made became popular! But there's all these "rip-offs" that are more popular still, and we're not happy about that. Especially since we think they're inferior.
Why, they don't even have "save game syncing across devices, a beautiful top screen and gorgeous little sharing cards for social media"!
You have to pay for Threes, and you can only play it on your phone, and furthermore only if that phone is made by Apple.1 Spending fourteen months polishing your flawless jewel, releasing the result under those kind of restrictions and expecting people to be content to look but not touch is, well, naïve. That someone spends a weekend reimplementing a version that works everywhere just for fun is hardly surprising, and thus the year-long Threes development process surely counts as a Very Poor Business Decision Indeed.
That a Threes-like game proceeded to take over the internet is something that nobody could've predicted. The internet is nothing if not fickle. But if any version was to take over the internet, it would most certainly not be Threes, unless Threes ran in a web browser and was available for free. Those requirements are mandatory for the kind of exposure that 2048 has garnered.
2048 is absolutely an improvement over Threes, in every way that counts. But 2048 went one step further. It's open source. The sheer bewilderment at this is evident in the MM article:
"What isn’t alright by me is a game that releases for free and makes no attempt to make money, which is what 2048 has done. It does nothing to monetise: it makes no advertising revenue; it has no broader cross promotional purpose and it certainly has no in app purchases to make money."
This guy made a game and just gave it away? What is wrong with him?
This mindset is what I loathe about the mobile world2, and part of why I don't own a smartphone. Everyone has an ulterior motive, usually money. It's natural and assumed. Nobody would ever do anything that wasn't to their advantage, and users are there to be exploited.
Let's be clear here. 2048 is not a "rip-off".3 2048 is not destroying value, it's creating it. 2048 is someone building on what has come before. The many 2048 variants are people building on what has come before. This is how culture works. This is how culture has always worked. This human tendency is what made the technology on which Threes depends possible!
Why is this news to anyone? Particularly the author of the MM article, but also the Threes developers. That someone considered Threes important enough, inspirational enough to build on should be cause for celebration, not consternation!
They aren't the only ones missing the point, of course. Ownership of ideas is accepted and commonplace today. Imagine for a moment what might've happened had the Threes team spent some of their fourteen months applying for a patent on the mechanics of their game. Likely they would've got their "no rip-offs" wish: 1024 could have been effectively nipped in the bud. Its successor 2048 would never have existed. And nobody would ever have heard of Threes.
If you don't consider that outcome an improvement (I don't), maybe it's worth pondering how we as a society could start encouraging this kind of creativity instead of denigrating it. But first we need to start accepting that "derivative" is not a dirty word.
(Full disclosure: I made a 2048 variant. And I have never played Threes.)
[1] Yes, there's an official Android port now, but not until over a month after the iOS release, which was quite long enough. Also iPads count as big phones for the purposes of this rant.
[2] And before that, the Windows world. Happily, there are communities where people cooperate to make and give away software, even entire operating systems, without any motivation beyond wanting to make something awesome. And for that I am truly grateful.
[3] rip-off /ˈrɪpɔf/ n. a copy, and that's bad.
8402
I've never been much of a fan of memes, much less participated in one. I really should know better. Still, I've had fun with this one.
First there was 2048, which by now needs no introduction. Then there was 2048-AI. The AI's minimax strategy resulted in it routinely calculating the worst possible positions for new tiles, so it could avoid potential disasters. This prompted a lengthy discussion on HN1 about whether minimax was really a good idea when in the game new tiles were placed randomly, and that it was arguably optimizing for the wrong thing, resulting in needlessly conservative play.
Then there was 2048-Hard, which demonstrated that purposeful tile placement really did make the game significantly more difficult. Almost impossible, in fact, even for the AI.
Whether 2048-Hard is an argument for or against minimaxing isn't clear. But a different idea occurred to me: rather than fixing the AI so that it assumes random tile placement, why not fix the game so that it matches the AI's model more closely?
Thus was born 8402, an inside-out variation where the AI is not on your side at all. As well as an interesting (and almost entirely unlike 2048!) game in its own right, hopefully 8402 offers some insight into the original too.
[1] See also this Stack Overflow question.