Applause
So a friend of mine tweeted about something that bothers him. It bothers me too, just in the opposite direction. Maybe finding someone with actual opinions on this is my chance to resolve something that's puzzled me my entire life.
Humans do a lot of things that baffle me. Applauding is one of them. In my world, if you go to see musicians perform, it is only polite to shut the hell up and not disrupt the experience for other audience members or interrupt the concentration of the performers. Optionally, you can show your appreciation afterwards using the bizarre but societally-approved method of repeatedly smashing your palms together1, but don't do it in the middle of a piece. If you're not sure if it's still the middle of the piece, err on the side of extreme caution to avoid making an ass of yourself. To my mind, even doing it immediately afterwards can ruin the moment. Me, I'd give it a good twenty seconds of silence first, particularly after a quiet ending.
It could of course be worse. It could be a rock concert, where clapping and whistling and screaming and making a general hullabaloo is considered SOP. And what do the organizers do? They turn the fucking volume up to compensate, to the point that earplugs are recommended accessories for frequent concert-goers. Do Not Want.
My conclusions have largely been "people are weird, film at eleven" and "avoid live music concerts, particularly rock concerts". Sadly this is insufficient, because live recordings are a thing. Audience noises do not add "atmosphere" to a recording, they just reduce the signal-to-noise and make it more annoying to listen to.2
Anyway, back to the tweet. "I let people applaud whenever they fucking wanted to in my concerts." To my mind this misses the point entirely. You can't prevent people from applauding! This is the whole problem! Trying to dissuade people beforehand would indeed almost certainly get you perceived as a stuck up wanker, and thus as a performer there is simply nothing you can do.
This is one of many reasons I don't give concerts. A minor one, admittedly, overshadowed by the fact that I suck and I have no idea how to find a venue or an audience3. Still, the possibility of being applauded at mid-musicking haunts me, because I know I would react badly.
Music is important. Don't ruin it by clapping. Please?
(I guess in addition to being a stuck up wanker I am also a contrarian windbag for not wanting to reply within 140^H^H^H280 characters.)
[1] I'd be delighted if people were to adopt the mould-friendly thumbs-up.
[2] Not to mention that, for a given amount of practice, it is much easier to make an accurate recording with modern editing technology than it is to make an accurate real-time performance. Mistakes do not add atmosphere either.
[3] There's also that one time when I was ~12 when I bowed to the wall because people assumed I knew what bowing was for. I didn't, and was confused when faithfully executing the macro I'd been given earned me a reprimand afterwards.
What's wrong with Threes 1
A few weeks ago, when the 2048 craze was at its height, this Mobile Mavericks article (mirror) was posted on HN. (Go read it. Go read it now. I'll wait.)
To say I disagree with this article would be putting it mildly. But hey, someone is wrong on the internet. It happens all the time.
However, here's the Threes team weighing in on the topic. They say essentially the same thing, only more diplomatically: woo, something we made became popular! But there's all these "rip-offs" that are more popular still, and we're not happy about that. Especially since we think they're inferior.
Why, they don't even have "save game syncing across devices, a beautiful top screen and gorgeous little sharing cards for social media"!
You have to pay for Threes, and you can only play it on your phone, and furthermore only if that phone is made by Apple.1 Spending fourteen months polishing your flawless jewel, releasing the result under those kind of restrictions and expecting people to be content to look but not touch is, well, naïve. That someone spends a weekend reimplementing a version that works everywhere just for fun is hardly surprising, and thus the year-long Threes development process surely counts as a Very Poor Business Decision Indeed.
That a Threes-like game proceeded to take over the internet is something that nobody could've predicted. The internet is nothing if not fickle. But if any version was to take over the internet, it would most certainly not be Threes, unless Threes ran in a web browser and was available for free. Those requirements are mandatory for the kind of exposure that 2048 has garnered.
2048 is absolutely an improvement over Threes, in every way that counts. But 2048 went one step further. It's open source. The sheer bewilderment at this is evident in the MM article:
"What isn’t alright by me is a game that releases for free and makes no attempt to make money, which is what 2048 has done. It does nothing to monetise: it makes no advertising revenue; it has no broader cross promotional purpose and it certainly has no in app purchases to make money."
This guy made a game and just gave it away? What is wrong with him?
This mindset is what I loathe about the mobile world2, and part of why I don't own a smartphone. Everyone has an ulterior motive, usually money. It's natural and assumed. Nobody would ever do anything that wasn't to their advantage, and users are there to be exploited.
Let's be clear here. 2048 is not a "rip-off".3 2048 is not destroying value, it's creating it. 2048 is someone building on what has come before. The many 2048 variants are people building on what has come before. This is how culture works. This is how culture has always worked. This human tendency is what made the technology on which Threes depends possible!
Why is this news to anyone? Particularly the author of the MM article, but also the Threes developers. That someone considered Threes important enough, inspirational enough to build on should be cause for celebration, not consternation!
They aren't the only ones missing the point, of course. Ownership of ideas is accepted and commonplace today. Imagine for a moment what might've happened had the Threes team spent some of their fourteen months applying for a patent on the mechanics of their game. Likely they would've got their "no rip-offs" wish: 1024 could have been effectively nipped in the bud. Its successor 2048 would never have existed. And nobody would ever have heard of Threes.
If you don't consider that outcome an improvement (I don't), maybe it's worth pondering how we as a society could start encouraging this kind of creativity instead of denigrating it. But first we need to start accepting that "derivative" is not a dirty word.
(Full disclosure: I made a 2048 variant. And I have never played Threes.)
[1] Yes, there's an official Android port now, but not until over a month after the iOS release, which was quite long enough. Also iPads count as big phones for the purposes of this rant.
[2] And before that, the Windows world. Happily, there are communities where people cooperate to make and give away software, even entire operating systems, without any motivation beyond wanting to make something awesome. And for that I am truly grateful.
[3] rip-off /ˈrɪpɔf/ n. a copy, and that's bad.
Ranting: in abeyance
I had a rant planned, but just as I was getting nicely worked up and frothy I happened to read this. And, well, I know when I'm beat.
That is all.
SSL (mis)adventures
So I've been meaning to set up SSL on here for a while now—the web being unencrypted by default these days is just silly—and reading this gave me the impetus to give it a try. ($0, you say? Under an hour, you say? Sounds good to me!) My experiences were... frustrating.
Step 1: Register with StartSSL. After I grudgingly gave them all my personal information, I was provided with a client certificate, which my browser (Chromium) promptly rejected. "The server returned an invalid client certificate. Error 502 (net::ERR_NO_PRIVATE_KEY_FOR_CERT)". The end.
Since the auth token they emailed me only worked once, I couldn't try using another browser. So, unsure what to do (and thinking they might appreciate knowing about problems people have using their site, so they can fix them or work around them or even just document them), I fired off an email.
The response I got was less than helpful: "I suggest to simply register again with a Firefox. Make sure that there are no extensions in Firefox that might interfere with the client certificate generation." Gee thanks, I would never have thought of that. And nope, I can't register in Firefox, my email address already has an account associated with it. Perhaps naïvely, I thought StartSSL might frown on people creating multiple accounts (or might like to take the opportunity to purge accounts that will never be used because their owners can't access them), which was why I didn't just create a second account using a different address in the first place. Still, lesson learned, second account created, no problems this time round. Bug fixed for the next person to come along? Not so much.
Step 2: Validate my domain. Going into this I was thinking "Hmm, will I need to set up a mail server and MX record so I can prove I can receive mail at my domain? Will the email address WHOIS has suffice? What address does WHOIS have, anyway?"
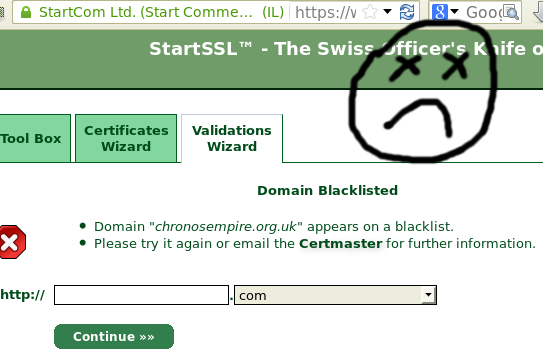 This was premature. Apparently the domain chronosempire.org.uk is blacklisted. Sadness. Not having any clue why, I fired off another email. Turns out it's Google. Google blacklisted me, claiming
"Part of this site was listed for suspicious activity 9 time(s) over the past 90 days."
This was premature. Apparently the domain chronosempire.org.uk is blacklisted. Sadness. Not having any clue why, I fired off another email. Turns out it's Google. Google blacklisted me, claiming
"Part of this site was listed for suspicious activity 9 time(s) over the past 90 days."
Nine times? WTF, Google?
The reply continued: "Unfortunately we can't take the risks if such a listing appears in the Class 1 level which is mostly automated. We could however validate your domain manually in the Class 2 level if you wish to do so.". I am confused as to what risks there are to StartSSL (I thought they were only verifying my ownership of the domain, which I'm pretty sure is not in doubt), and how those risks would go away if I paid them more than $0 for a Class 2 cert.1
Still, StartSSL is just the messenger here. Google recommends I use Webmaster Tools to find out more, so I dig out my rarely-used Google account, get given an HTML file to put in my wwwroot, let Google verify I've done so, and finally I find out what this is about.
I have a copy of Kazaa Lite in my (publicly-indexed) tmp directory. Apparently some time around June 2004 I needed to send it to someone, and it's been there ever since.2 This should not come as any surprise to anyone who knows of my involvement in giFT-FastTrack, but more to the point, Kazaa Lite is not malware. Not only is it not malware, it not being malware is the entire reason for Kazaa Lite's existence.
Sadly, whether it is or is not malware is irrelevant. "Google has detected harmful code on your site and will display a warning to users when they attempt to visit your pages from Google search results." Nice. So now I have to refrain from putting random executables in my tmp dir in case they make Google hate me? (Total hits for the file in question over the past few months: 14. Hits that weren't Googlebot: zero. In fact, I'm pretty sure not a single actual human has fetched it in the past, say, five years.)
Anyway. A quick dose of pragmatism and chmod later and my site is squeaky-clean! Now I guess I have to wait 90 days for Google to concur. Which is perhaps just as well, as I've already spent substantially more than an hour on this, I've not even started configuring my web server or making a CSR, and my enthusiasm is as low as the number of people desperate for my copy of Kazaa Lite.
[1] Maybe I'm being overly cynical here and they would actually use the money to check... something? What? I have no idea.
[2] I firmly believe in not breaking URLs unnecessarily. That's my story and I'm sticking to it. It has nothing whatsoever to do with me never cleaning up my filesystem.
WebDAV and the HTTP PATCH nightmare
HTTP 1.1 defines a way of retrieving part of a file1, namely the Content-Range header (plus Accept-Ranges and the 206 status code). This was widely implemented by web servers and is now ubiquitous, meaning that clients can resume partial downloads and/or seek in remote files (think video) with impunity. HTTP 1.1 also introduced the PUT method to create and update files, which was later used in WebDAV.
Clients might want to do partial updates for much the same reasons they want to perform partial retrieval: because network connections might die part way through big requests.2 The obvious way to perform partial updates is to send a PUT request with a Content-Range header, and indeed Apache supports such requests and behaves as expected.3
This seemed so clear and straightforward a solution to me that, when implementing a WebDAV client, I tried this idea before even reading the spec, was gratified that it worked on my test Apache server, and called it “done”.
Sadly, there's a snag.4 HTTP 1.1 defined PUT as being “idempotent”, which is allegedly incompatible with partial updates. RFC 5789, thirteen years after HTTP 1.1, decided to address this with the HTTP PATCH method. It says:
“The PUT method is already defined to overwrite a resource with a complete new body, and cannot be reused to do partial changes. Otherwise, proxies and caches, and even clients and servers, may get confused as to the result of the operation.”
OK, let's assume for the minute that this is true, and this RFC is an earnest attempt to solve the problem.
RFC 5789 documents a way of sending “patch” requests to existing files. It allows multiple patch formats, and documents how to enumerate the list of formats, but—and this boggles my mind—does not document, or even hint at, any examples of such formats.5 Indeed, nowhere does such a list exist. Again from the RFC:
“Further, it is expected that different patch document formats will be appropriate for different types of resources and that no single format will be appropriate for all types of resources. Therefore, there is no single default patch document format that implementations are required to support.”
Why, why would they do this? It's HTML5 <video> all over again.
Unsurprisingly, given such an underspecified standard (yes, RFC 5789 is Standards Track!), no WebDAV servers have bothered to implement it.
Actually, that's not quite true. SabreDAV is making a valiant attempt. Since there's not enough information in the standard to actually implement, PartialUpdate defines a SabreDAV-specific patch format with the same functionality that Apache has supported for PUT with Content-Range for the past twelve years, namely updating a simple byte range.
How many clients support this SabreDAV-specific behaviour? To the best of my (and google's) knowledge: none.
But is PATCH even solving a real problem? RFC 2616 has the following to say about PUT requests:
“The recipient of the entity MUST NOT ignore any Content-* (e.g. Content-Range) headers that it does not understand or implement and MUST return a 501 (Not Implemented) response in such cases.”
To me, this reads as “Content-Range is just fine for PUT requests, but if you don't implement it, make sure you throw an error instead of silently ignoring it”. For this to actually mean “you MUST return 501 if the request contains a Content-Range that is not the entire file” seems perverse. The possibility exists that the authors of RFC 2616 overlooked something in their implicit approval of Content-Range for PUT requests, but I have my doubts.
As for idempotence: it is true that PUT requests are defined as being idempotent, and thus proxies, caches, clients and servers are allowed to optimize accordingly. But partial PUT requests are idempotent! Writing part of a file more than once has precisely the same effect as writing it once.
Multiple partial PUT requests for different parts of a file may of course not be idempotent (depending on whether the ranges overlap), but this isn't a problem! Multiple differing complete PUT requests are not idempotent either, indeed, HTTP 1.1 explicitly states that “it is possible that a sequence of several requests is non-idempotent, even if all of the methods executed in that sequence are idempotent”.
Where I think the confusion lies is the notion that the state of a file after a (successful) PUT request is completely specified by the request, and does not rely on the previous file contents. Nowhere that I have found has this been claimed, so presumably any software that assumes it to be true can expect nasal demons.
I do not know whether such broken software exists. It might do. Nonetheless, I cannot think of a single case where, given the assumptions in HTTP 1.1, partial PUT requests might cause a problem. Clearly the authors of Apache considered it sufficiently non-problematic to support them. lighttpd supports them too. Whether other WebDAV servers that declined to did so because of fear of misbehaviour or because they considered resumable uploads a corner case too obscure to be worthwhile implementing is anyone's guess (though if it's the latter I will happily denounce them for skimping).
That I can't think of any possibilities for badness doesn't mean they don't exist, but examples would go a long way to making me a believer. Meanwhile I can't help but wonder what the authors of RFC 5789 (which, as a standard, “represents the consensus of the IETF community”) considered so worrying, and why they proposed such a baroque non-solution to a seeming non-problem.
So where do things stand if you want resumable uploads over WebDAV?
- If your WebDAV server is Apache (or lighttpd!): use PUT with Content-Range, and ignore what RFC 5789 says about this being forbidden.
- If your WebDAV server is a recent SabreDAV: use PATCH with a SabreDAV-specific Content-Type.
- If your WebDAV server is anything else (nginx, IIS, ...) you're probably out of luck.
And this is why we still don't have a sane standards-based network filesystem.
[1] For the pedants: yes, the things that an HTTP server serves up needn't be files, and indeed the official terminology is “entity” or “resource”. But I'm going to call them “files” for simplicity, in deference to the 99% of the time that this is the case.
[2] There are other reasons, of course. But this is the biggie.
[3] WebDAV code first appeared in Apache's repository in June 2000, with this functionality already present. See here, around line 1120.
[4] You saw that one coming, right?
[5] Well. “The determination of what constitutes a successful PATCH can vary depending on the patch document and the type of resource(s) being modified. For example, the common 'diff' utility can generate a patch document that applies to multiple files in a directory hierarchy.”—wait, so web servers are supposed to understand diffs? Diffs that apply to multiple files? Talk about scope creep!